
Deciding What to remember and what to forget
Curating Context
A deep dive into contexts, curating the relevant information for LLM sessions, plus a demo for production.

Reviewing my AI workflow
Human in the loop
My diary of LLM sessions and lessons learned for the last months: prompting, planning and implementing code features, creating skills, agents, subagents, and managing context.

Separting Frontend
from data and logic
Arriving at an architecture
A journey towards a three-layer architecture to scale frontend applications: a presentation frontend, a Backend for Frontend (BFF) middleware layer for data transformation and business logic, and a backend core.

Shifting focus
Working with AI
AI tools have shifted my focus from writing code to architecting systems and engineering context. New standards like MCPs and Spec-driven development help AI agents do more.

Style and consistency
Design systems that adapt
The right design system isn't the most sophisticated one. It's the one that matches your current team and app constraints while remaining flexible enough to adapt as you grow.

Photo by Pierre Châtel-Innocenti on Unsplash
May 2026Reviewing my AI workflow
Human in the loop
My diary of LLM sessions and lessons learned for the last months: prompting, planning and implementing code features, creating skills, agents, subagents, and managing context.
Init
First steps and lessons learned from interacting with LLMs using a single promptPerhaps the first and a very important observation is that LLMs (Large Language Models) are better at criticizing than generating or creating text or code. Also that the quality of my input is directly related to how satisfied I was with the output. After all, it is an super advanced auto-complete. The more specific what you start with, the more the LLM can zoom in to its own network of tokens and return a more relevant guess of how the pattern continues.Besides clearly specifying what you want, here are a few techniques of what was then super hyped as "prompt engineering":- Personas: Assigning expertize and a voice to the response narrows the focus of the LLM.- Context: Adding detailed facts, relevant URLs and data helped reduce hallucinations and inaccuracies.- Output Requirements: Setting the format, tone, and word limit to avoid verbosity.- Zero-shot vs Few-shot: Giving reference examples of the desired output is almost like a mini added layer of learning.- Chain of Thought: Asking the AI to think step by step before providing a finished output helps in two days. First, it forces the answer to be built slower and leaves less room for a small error to compound. It also reveals the underlying reasoning or logic flow behind the steps of the generated result, so I can identify which part doesn't fit my criteria.- Trees of Thought: Exploring multiple reasoning paths simultaneously helps with comparing alternatives and even sometimes with finding unexpected creative solutions.- Adversarial Validation: Generating competing outputs by different personas and having one critic persona to review drafts before merging feedback into a refined final output.This last technique mimics the highly successful GAN training architecture developed by Ian Goodfellow which was a breakthrough in image generation in 2014. It echoes the initial impression that "LLMs are better at criticizing than creating" and adds "so let them do that to their own work." This is the start of an internal review system for the generated results as well as a hint towards subagents, and I will come back to these two points in more detail later.The period of trying out and experimenting with all these techniques and really taking the first steps into discovering what the LLM can do was amazing. Before running into its limits, this was an open field of figuring out what of my current tasks the AI can handle from summarizing to rewriting, from researching a new API to fixing bugs in code and even refactoring an old application.It was in a sense overwhelming too, and because the output was rendered so quickly, I was asking more questions faster. Mostly I got great results, but every now and then when I didn't have the patience to sit down and draft the specs before running a prompt I didn't get what I was hoping for.Perhaps this is the most important lesson I got from this initial period and one which I still prioritize today. It's key to first sit down and write down the specs of the desired output, otherwise the process of getting there will be usually longer and more complicated. As one Youtuber put it simply:"The AI can only be as clear as you are."
Markdown
As my LLM outputs got better, I began to organize my prompts, contexts, and output specs into separate folders. I also began to adopt command line clients (or harnesses) like Gemini CLI, OpenCode, or Pi to make LLM requests from the terminal, run bash commands, and write the responses directly into files. This made my workflow much easier yet my biggest inconvenience at the time was the input format of the context files, which in addition links varied between plain txt. word documents, and PDFs. So what I needed was a format which is the easiest for the client to read and write into, and also for me to be able to review and edit.I didn't take long to realize that markdown is exactly the ideal format. I didn't need to reinvent the wheel. I was already using the format in readme files in all my git projects. It's almost a plain txt file, so easy for the AI client to parse and read; it has basic structure using section headings and numbered lists. And what's equally important, it renders beautifully on my screen.This is so obvious now that I will stop here and only refer this article for more about why markdown is so perfect for the job.My tools for working with markdown right now is using the Zed code editor for browsing and using Typora reading and writing./initWith the CLI clients, I could also work with multiple files or directories at once and point the model to read or write specific files by using the @ symbol. Once the markdown files were organized well in a new project folder: instructions, persona(s), output specs, reference examples, and context files, I can hit Enter, grab a coffee and wait for the model to cook. When the task was more trivial, I would even only provide an example input and output and run /init in Gemini CLI and it would generate the context file in markdown for me and use it later as the needed reference. I think this command is one of the most underrated genius skills of an AI client. In the docs, it's described as "To help users easily create a GEMINI.md file, this command analyzes the current directory and generates a tailored context file, making it simpler for them to provide project-specific instructions to the Gemini agent."This workflow was simply super. I helped me accomplish so much project research, writing proposals and documentation, and planning and implementing new features in my existing apps.
Skills
After frequent calls to specialized project-specific tools and prompts, I started to organize these instructions and the related commands into their own sub directories. This is how skills were created, and they are especially valuable for a team to make sure some processes are run consistently by all of its members. So what are skills? According to AgentSkills.io:Agent Skills are a lightweight, open format for extending AI agent capabilities with specialized knowledge and workflows. At its core, a skill is a folder containing a SKILL.md file. This file includes metadata (name and description, at minimum) and instructions that tell an agent how to perform a specific task. Skills can also bundle scripts, reference materials, templates, and other resources.They are basically a set of markdown files that give the model specific instructions and access to tool and resources that help perform some actions. The main difference between general context files which are persistent and are read as part of my context for every session, skills work more on an on-demand basis. They are like a special set of tools which the model only uses if they fit the problem they are trying to solving.Since they are so easy to share, I could even install them from the open agents skills at https://www.skills.sh/I found myself creating and using more skills, and some where quite different from each other depending on the specific project I was trying out.Most of the newly packaged skills were subfolders with another set of markdown, usually saved after a new tool was developed, co-researched and written with the help of the chat or CLI client. Sometimes I even pointed the client to the documentation of the needed URLs and API calls to create a new skill.So the agent can now create its own skills, given the description of the skill, how it works, and its scope.Is it the moment near the critical one of self-improvement where another intelligence can make a better version of itself (or the Singularity 🤯?) I think we are not there yet. The skills is not part of the LLM. It can improve its external skills but not its core brain./planThere was two additional helpful techniques that I found myself using over and over again that I made them a standard. First was to add a GUIDELINES.md file that has a few Dos and Dont's, usually more Don'ts than Dos, to give the LLM my preferences and coding style. The second was that before each session to set a to do list, and update it with what's done afterwards. Also to keep the reasons behind the choices made while completing these tasks in a separate md file for future reference.When the LLM was too eager to finish a given complex task, I had to force them to think first and weigh alternatives, and then present a step-by-step plan a la Chain of Thought. This is exactly what /plan mode excitability does which now comes bundled in most AI harnesses. In addition, there are more tools and frameworks like Spec-driven development to make this method formal, usually involving a multi-step process: Specify, Plan, Tasks, Analyze, and Implement. But the steps of updating the context and todos before and after session gave my process a welcome sense of autonomy and continuity.
Agents
When most people think of AI agents, they think of a fully autonomous actor that can read data of webpages and send emails. Due to the high error ratio and that we are still in the era of stochastic AI responses, I realized I didn't want this kind of agent, definitely not one thats generates tens or even hundreds of pull requests. What I had already in each of my project folders was a very capable agent. This is how the folder structure looked like at this point.

So a project folder with an AGENT.md (the file that tells the LLM how to work in your project), some skills, and context: that’s already an agent. The curated context which we will dive deeper into turns the model into a specialist in whatever task or field I was working on.In short, "the folder is the agent".To use the more general Google definition: "AI agents are software systems that use AI to pursue goals and complete tasks on behalf of users. They show reasoning, planning, and memory and have a level of autonomy to make decisions, learn, and adapt." Too general? 🤔ComplexityEarly on, I decided that any generated code must come with its own description and an architecture explanation. These help me and the agent understand the codebase, and they also help me to review the important changes in it and to identify future bugs.The shorter I can manage to document this context, the better the results I got. I will go back to more on the importance of context point soon below.I realized I didn't need too many folders or many agents, and I didn't want the agents to generate tens or hundreds of pull requests.The idea of humans as the bottleneck even though small AI mistakes easily grow exponentially when adding a thousand new features or functionality, the same as with humans even though review agents can do all they can to help when they are designed well.This is not a fault of the agents but complexity increases in any codebase or project with its size, and it doesn't matter how this new content or complexity were added or who added them.Products built 100% by agents are not efficient. It creates technical debt too quickly and the agent doesn't have the full context anyway and they start to do what is asked of them by making quick fixes or hacks locally and ignore the remote bugs they just created in other parts of the codebase or even change some global setups.It's not that my intervention is only needed to do minor tweaks and fix errors. It was needed to define and design what's critical: the user experience, the APIs, and the architecture.
Scope and Subagents
One agent can sometimes know and be doing too much at once. Then It's more efficient to limit the scope of each task, break the main session or request into parts and create a sub-session that only knows and focus on a specific task in a sort of hierarchy of tools and resources.This spliting of the main agent's boarder context helps a lot with consistency because each sub session's agent or subagent opens their own smaller context window and works only with information that's relevant to what they are doing. You can think of it as the difference of what the main agent knows vs what is needed for one smaller sub task.This is precisely what subagents are. They are specialized agents that operate within a main session performing a specialized task. For example, in a software development session, a a lead agent can use distinct subagents for roles such as an Explore subagent to search for files, a code-reviewer subagent to check for bugs, and a test-runner subagent to verify changes. Or in customer support apps, an orchestrator agent delegates incoming tickets to specialized subagents that concurrently check account history, search knowledge bases, and draft responses.The main benefits of subagents being context isolation and parallel processing capabilities. While the latter is more used where one is orchestrating a swarm of agents 🤦🏾, I am more interested in the effect of scoping by subagents on context. This is because context drift is, by far, the biggest issue facing the people and agents using LLMs with their current design today.
Context
We all faced this problem. As a conversation with an LLM gets longer, they start to forget things, ignore clear instructions, or even worse they start to seriously hallucinate. And yes it's frustrating as hell. This is context drop or drift, and I guess it's time to talk about what context really is.Context is the information that the current LLM session can access, understand, and use to generate their responses. It's a kind of short-term memory, and the analogy between the model and its context as that of the computer's CPU and its working memory or RAM comes close.Depending on how it is managed, the context may include the full chat history or, if compressed, it may contain only what is relevant to keep. The context window is the maximum size of the information the session can handle, and it's measured in tokens. Starting with 20,000 tokens a few years ago, the current state of the art context windows stand at 1 Million tokens (about 1,500 pages of standard text or 100,000 lines of code), which is the case for GPT-5.4, Claude Opus 4.6 and Gemini 3.1 Pro.There are many plausible reasons of why the LLM's attention dilutes as the context grows, and on the other hand I read studies that suggest that repository-level context files may reduce task success rates. I saw in my own experience that, regardless of the model used, curating what the model knows makes a big impact on its output, and that the shorter more-focused contexts perform better than long cluttered ones.So how can we keep the context short as the conversation gets longer?What we have here is a bit different from all the tool setup techniques I covered so far in this article. This is a scaling problem, i.e. an engineering problem. I split the context engineering part with a deeper analysis of the context drop, its reasons, recent solutions, and how to build a context management system for AI applications in production in a separate article.

Read Curating Context
Attention vs Reasoning
To understand the context bottleneck and other limitations of LLM models, let's take a wider look at what happened in the field of machine learning since 2017. While we are at it, I will try and make what would be soon really embarrassing predictions of where it's heading.So let's go back to the paper that started all of it. Neural networks (along with many other machine learning models) existed longer before 2017, then "Attention Is All You Need" came out and its results were simply ground-breaking. Its Google authors applied attention ("a method that determines the importance of each component in a sequence relative to the other components in that sequence"); in plain English, they made neural networks that can understand what words in a sentence meant in relation to each other. This technique generated much more coherent responses than ever before and it effectively made us believe that the chatbots understood what we say to them.While the LLM responses we got back were auto-complete with advanced attention, the were intelligible and they did relate to the prompt we inputed. Yet at their core, the responses are the output of a stochastic process, meaning that you never get the same response twice for the same prompt. Plus their success/failure rates are not evaluated for the current individual prompt; on the contrary, the LLM is trained as a whole beforehand on huge amounts of past data.The lack of response evaluation is what results in tight system prompts to prevent the model from giving unethical or harmful answers (i.e a harness), and also in effectively testing each new model in production on the public and against hundreds of non-standard benchmarks. Many of the techniques discussed in this post to create a functioning agent are workarounds to this main unpredictability limitation (by using personas, chain of thought, adversarial validation, and curating context).The theory behind how the LLM choses a specific output response remain quite opaque. We don't have a mental model of why language models excel in tasks as varied as they do in, not even a foundation of a theory. We don't know how they work so well, but they do work phenomenally well.At their core, LLMs are stochastic machines.This is not what I think of when I think of "intelligence." There can be an element of randomness which is part of human and animal brains but not at its core. Response evaluation is a critical signature of reasoning, problem-solving, or thinking in general. I believe pattern recognition of a system's constraint's accounts for than half of what we call intelligence and science in general.Intelligent systems and people don't give random answers to questions they don't know how to answer. They can say "I don't know." An intelligent system weighs options by default, not as part of external instructions, and it moves in the best direction according to these initial weights or impressions. This is not done in a brute force way but in a smart way. Also intelligent systems have another common feature we don't see in LLMs: They find out quickly which problems are hard and need more work, and which ones are trivial.Energy Based ModelsOne research direction which may provide a solution of all these drawback are "energy-based models." Yann LeCun and other researchers have been working on this idea for a while (since the 80s), and they are quite different from LLMs in that they view problem-solving as constraint satisfaction instead of auto-complete.The name and technique is inspired by natural systems in physics which try to settle to an equilibrium state where energy is at a minimum. Similarly, the model explores the possible states/solutions and moves in a direction to minimize an energy function to "reason" about the best answer. This is done with the help of a gradient descent algorithm as used in neural networks, and it results in less randomness in the final answer, by design.You can find more about the development of energy-based models in the new initative Logical Intelligence and a video review here: Energy-Based Models Explained: The AI Beyond Next-Token
This post and the next one about context engineering will be published as a series of Medium posts here.

Photo by Pierre Châtel-Innocenti on Unsplash
June 2026Deciding What to remember and what to forget
Curating Context
Two observations stand out in longer conversations with an AI agent or chatbot. The first is something almost everyone have noticed; the quality of the LLM responses degrades heavily the longer the conversation gets. Details get lost, clear instructions are ignored, and it seems like the LLM begins to suffer from memory loss but not exactly.Second, the model remembers quite well the last couple of prompts and the first few but the middle details get somewhat blurry and have to be reiterated. The degree to which this effect occurs depends on the context window we are working with. It's as if they struggle to focus on the big picture as a whole and their attention becomes diluted in the middle part.
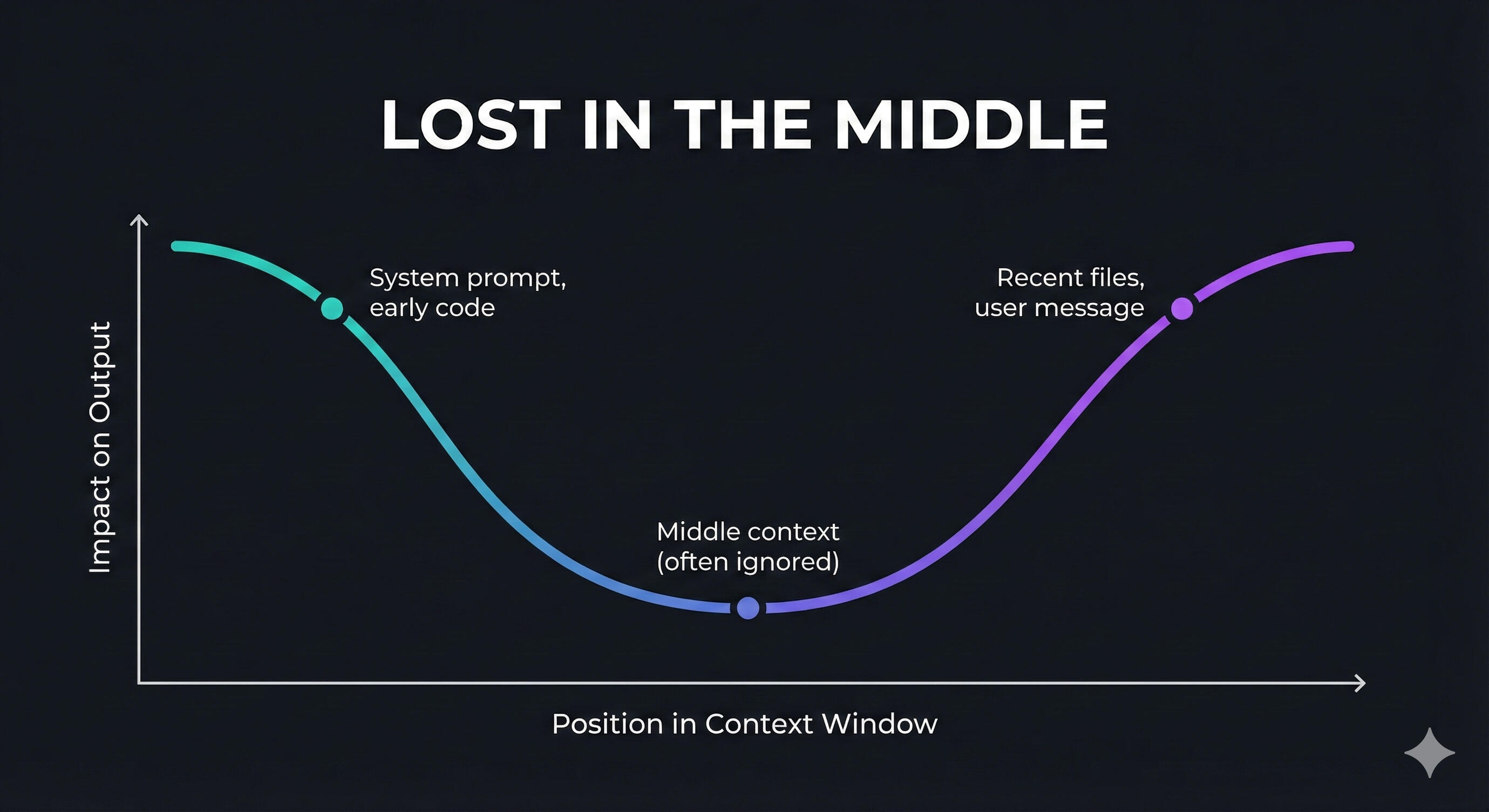
Generated graph (src)
+ the first arXiv paper documenting this phenomenon
For a metaphor, it may help to think of a LLM as a new kind of operating system where the model is the CPU, and the context window is the RAM. Just as a computer slows down when RAM fills up, an agent's reasoning degrades when the context window gets crowded.So in this post, I will dig deeper into this topic and cover: what's in a context window, how it affects the quality of responses, the reasons why the quality degrades, the solutions available to fix this issue, and how to build a context management system for agents in production.
TL;DR: A deep dive into contexts, curating the relevant information for LLM sessions, plus a demo for production.
What's in a context window?From Anthropic's "Effective context engineering for AI agents" article , they define context as "the set of tokens included when sampling from a large-language model (LLM)" and context engineering as the problem of "optimizing the utility of those tokens against the inherent constraints of LLMs in order to consistently achieve a desired outcome."In practice, you can see Claude's context in a session and it looks like this:
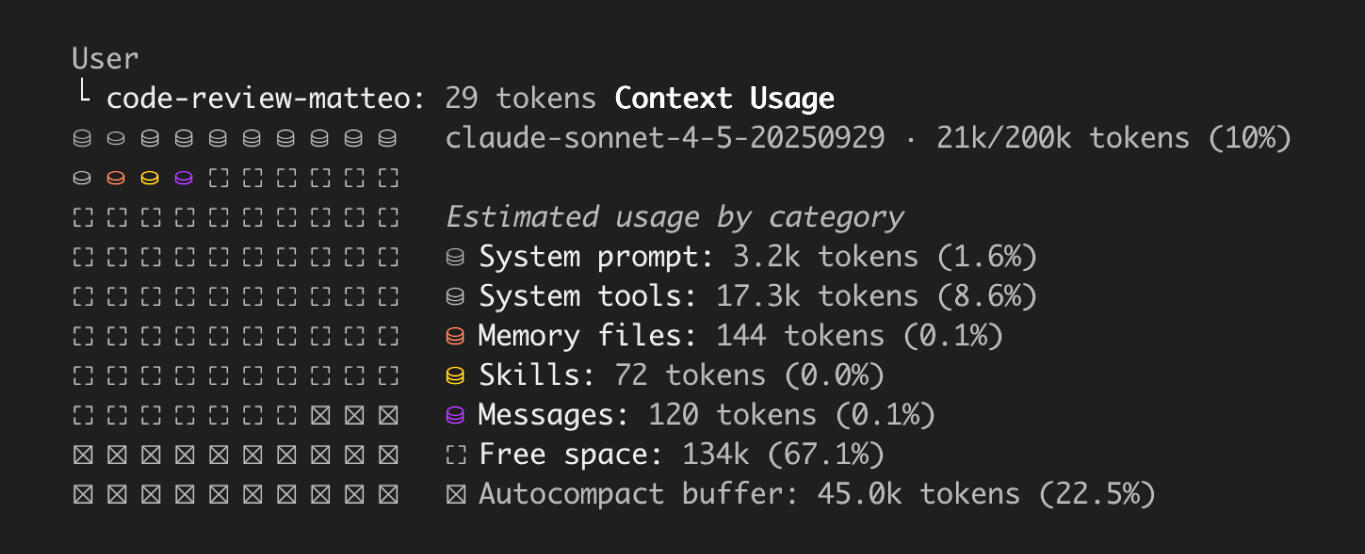
For such a 200k tokens context window in an AI harness, there is always a system prompt and tools. These are the primary instructions and tools or Constitution of the agent. You can build on top of them but you can not remove them. You can add your own agent prompt on a secondary level, and your project's specialized tools and skills.
Memory files are a summary of your preferences that the agent decides to remember, either for short-term in the current session or long-term across multiple sessions, and it does so based on the prompts' instructions. Finally comes the messages: the whole conversation history, or if it's too long and doesn't fit in the context window, it gets automatically compressed by the agent.
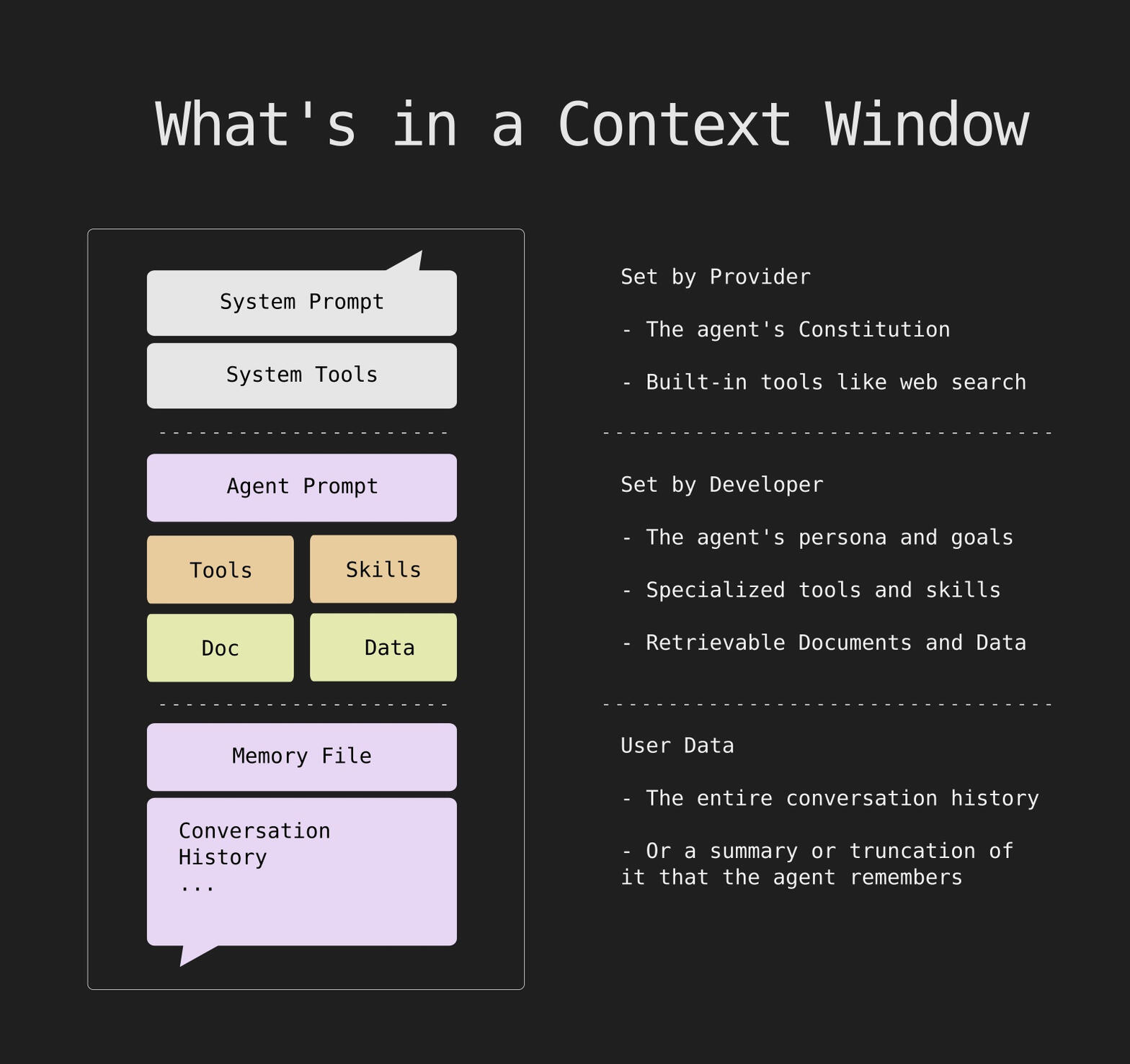
So pretty much, context is the totality of instructions and information that determines the response users for a specific LLM. This explains why Google describes context engineering more generally as "the architecture of meaning for artificial intelligence." In more down-to-earth terms, Context Engineering is "Assembling exactly the right information at exactly the right time."In any case, "Context is a critical but finite resource for AI agents."
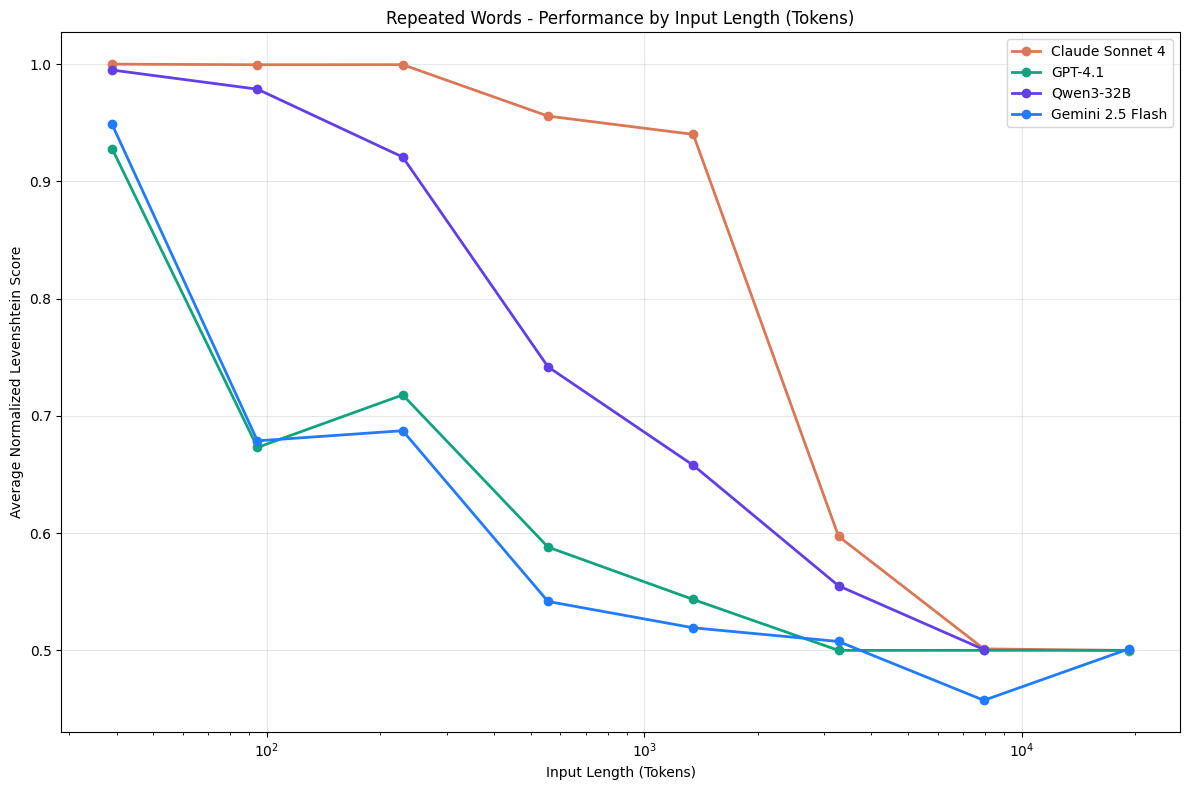
Symptoms and Reasons of Context DropIn a study done by Chroma last year on 18 LLMs, researchers found out that that the models don't use their context uniformly and their performance grows increasingly unreliable as input length grows.They benchmarked the models against a "Needle in a Haystack" test, where they placed a random fact in the middle of a long context and test whether the model knows about it. Varying the amount of irrelevant content before and after the "needle" fact, The result confirmed that even advanced models are more distracted in longer contexts and conclude that "whether relevant information is present in a model’s context is not all that matters; what matters more is how that information is presented."
Here are the three major failure modes that occur when context management fails:1. Context Pollution: Errors or hallucinations enter the context early in a session and are referenced in subsequent steps. Each step compounds the errors. Fix: Prune failed attempts and validate tool outputs.2. Context Clash: New information contradicts older ones. Fix: Establish a clear authority ordering (e.g., System prompt > Retrieved data > Memory files).3. Noise Accumulation: The model over-relies on recent history. This is basically "Lost in the Middle" effect where the context has a "dead zone" where source material or key constraints are present but functionally ignored. Fix: Continuous context compression.Leading AI platforms implement their own different methods to context management. For example, Claude Code uses hybrid retrieval (e.g., claude.md files) with auto-compression. ChatGPT Agent uses visual reasoning with screenshots with reinforcement learning for tool optimization. And Google's ADK gives context its own scoped pipeline and applies architectural principles to separate memory storage from presentation.The specific context management strategy to adopt depends on the kind of agent that will use it. For a custom-built solution that fits my own chat assistant AI agent, I will focus on using the Google approach and try to reduce noise accumulation as much as possible. Next, let's explore this direction in more detail and develop a functioning strategy for curating the best context for our agent.
Memory Hierarchy
Zero MemoryOne quick research detour before outlining the best practices to manage context.A February 2026 study by researchers at ETH Zurich and DeepMind found that repository-level context files like AGENTS.md generally reduce task success rates. You may have noticed yourself that LLMs sometimes underperform when given too large of a context file with many available tools and documentation. While the reasons for this observation are still unclear, I think it hints at a principle beyond the optimal size of the context, namely zero. LLMs are stateless machines and adding a memory state to them constraints them in ways we still don't fully understand.So I am adopting the principle to use as minimum of a context as possible. How is this doable in practice? By scoping the information on a need-to-know basis so that, by default, the main agent delegates requests to their subagents that can retrieve more relevant information to their subtasks. The best case scenario being that the subagents start with a clean context window.
CompressionThe first idea that comes to mind of how to make contexts smaller is to simply ask the LLM to summarize it because well they're pretty good at summarizing. While it might seem to a obvious solution, surprisingly its results turn out to be too inconsistent. And if the summarization prompt tells the model what to keep and what to discard, too much important information are lost in the process.A second option is to only keep the beginning thread of the conversation and let the LLM figure out the rest. While this works for short chats, quickly though, it becomes clear that this is too aggressive of a truncation and the agent ultimately forgets too much.Following the steps of Sally-Ann Delucia at Arize AI, the solution that works is a smart truncation strategy paired with a retrievable memory store. The successful strategy involves keeping the head (initial instructions) and tail (latest results) of the context, while moving the middle (older history and long tool results) into a retrievable memory store."We've found that this combination of truncation and memory has been really, really successful. So context decides what the model sees, memory decides what survives," according to Arize AI. Perhaps why it works is because it helps agents get enough of a glimpse at what's Lost in the Middle and at the same time doesn't overwhelm them with too much context.
Context Management System
Using this technique plus handing over tasks to subagents is the way to go. So let's outline a agent architecture that works like this for a specific example: a chat assistant for customers of a business after they booked their services. Each business uploads their products or services details, and the clients can interact with the chat to ask questions and request special accommodations.Architecture OverviewFor the purposes of this demo, I will use python with FastAPI and a vector database. The system is made up of four core main components:1. Context Manager: The engine that implements your smart truncation + memory strategy.
2. Main Agent (Orchestrator): The "front desk." It receives the user's message, analyzes the context, handles simple chatter, or hands off to subagents.
3. Subagents: Specialized agents with narrow scopes and specific tools.
* Knowledge Subagent: Queries the uploaded business details (RAG or markdown).
* Action Subagent: Handles booking modifications, special requests, and API calls to the DB.
4. Memory Updater : A periodic background task to update memory files.
5. FastAPI Backend: Handles real-time chat and file uploads for business details.The app structure would look something like this:

Now that we have the main parts mapped, let's go over how the prompt is sent over to the LLM service by the Context Manager. The request is dynamically constructed of a head, middle, and tail. While the head is fixed and the tail is the user's last few messages, the middle part is retrieved from a memory file that is updated on each N turns (e.g. on every 10 messages). To break the prompt down, it's composed of:• The Head (Fixed Context):
- System Prompt & Agent Persona.
- Current state data: User's name, Booking ID, current booking status.
- High-level business instructions (e.g., "You are an assistant for Resort X...").• The Middle (Retrievable Memory):
- Older conversation turns (e.g., messages older than the last 10 turns).
- Long tool outputs (e.g., the massive JSON result of a database query from 10 minutes ago).
Implementation: These are embedded and stored in a Vector Database (like Chroma or Qdrant) tied to the session_id. They are retrieved using the user's latest query and injected as a <Retrieved_Memory> block.• The Tail (Short-term Working Memory):
- The most recent N messages.
DemoYou can review full code demo at github.com/faltastic/context-manager-demo, and here I go over the main code sketches.Instead of blindly passing the Orchestrator’s entire conversation history (the Head, Middle, and Tail) down to the subagents, the Orchestrator acts as an intelligent delegator. When it routes a request, it generates a concise task_summary.The ContextManager then builds a custom, scoped context specifically for the target subagent, giving it only the data it needs to execute its job, stripping out irrelevant chit-chat and reducing token bloat.
1. The Context ManagerThe Context Manager creates different prompts depending on who is doing the thinking. The Orchestrator gets conversation history to understand intent, while subagents get strict, minimal data required for their specific tasks.Instead of querying a Vector DB on every single message turn, the Context Manager simply reads from a static text memory file for the Orchestrator's "Middle" block, keeping latency extremely low.
2.The Orchestrator Router
When the Orchestrator decides to hand off, it is required by the tool schema to provide a task_summary. It synthesizes the user's intent from the messy conversation history into a clean instruction for the subagent.
3. The SubagentsBecause each subagent receives a completely isolated, clean context, its risk of confusion is near zero.
4. The Memory UpdaterTo implement a periodic memory update as a background task (e.g., every 10 turns) instead of querying a Vector DB on every single message, we use a Rolling Summary / Memory File pattern.This function runs asynchronously every 10 messages. It takes the current memory file, the 10 recent messages, and asks the LLM to compress them into a new, updated memory file.
5. The FastAPI EndpointThe API layer acts as the traffic controller and trigger mechanism. It counts the unsummarized messages; if the threshold (e.g., 10 messages) is reached, it schedules the background compilation task and flushes the database history to reset the Tail.

For more background, read Human in the Loop: my diary of LLM sessions and lessons learned for the last months: prompting, planning and implementing code features, creating skills, agents, subagents, and managing context.

Photo by Pierre Châtel-Innocenti on Unsplash
Jan. 2026Separting Frontend
from data and logic
Landing on an Architecture
As a fullstack developer who's spent considerable time building with React and Next.js on the frontend and Node.js on the backend, I've learned firsthand how quickly frontend applications can become unmaintainable as they scale. My experience building Arti, a niche platform designed for the art community, taught me invaluable lessons about architecture, scalability, and the critical importance of separation of concerns.The Arti project required rapidly iterating on features like location-based features and user preference systems while constantly updating the frontend interface without disrupting existing functionality. What started as a straightforward prototyping exercise soon evolved into a complex web of interconnected logic. As features accumulated, I found myself wrestling with a growing tangle of problems: UI components intertwined with data fetching logic, business rules scattered throughout the codebase, and modifications that threatened to break entirely unrelated parts of the application. These scaling challenges made even simple prototype iterations time-consuming and error-prone.After experimentation with various architectural approaches (monorepos, microservices, and Jamstack configurations) I discovered a solution that elegantly balances both rapid development and sustainable scalability. By adopting a layered architecture pattern with Backend for Frontend (BFF) principles, I was able to completely decouple the user experience layer from data management and business logic. This article shares the architectural decisions, core principles, and practical implementation details that transformed Arti from a fragile prototype into a robust, maintainable platform.
TL;DR: A journey towards a three-layer architecture to scale frontend applications: a presentation frontend, a Backend for Frontend (BFF) middleware layer for data transformation and business logic, and a backend core.
Frontend Scalability Challenges
When you start prototyping, the frontend feels simple, just UI and some data feeds. But then auth, queries, and rules sneak in, and suddenly your React components are doing too much. For Arti, that meant big updates (like adding new tools or user options) risked breaking everything. My goal: Make the UI a light presentation layer that stays quick to tweak, while pushing data and decisions to the backend.When we talk about scalable frontend development, we're addressing multiple interconnected challenges that become increasingly urgent as projects grow. Some common chllanges to scalability:Code Organization and Complexity: When prototyping, the frontend appears deceptively simple, basically some UI components and data connections. However, as applications mature, authentication logic, complex queries, and business rules inevitably proliferate. Components begin implementing data fetching alongside presentation, state management logic bleeds into UI concerns, and simple UI updates risk cascading failures throughout the application. For Arti, major updates like adding new tools or user capabilities threatened the entire system's stability.
Performance Bottlenecks: As frontend applications become more complex, inefficient code patterns, excessive re-rendering cycles, and direct database access can dramatically degrade performance and slow load times. These issues become exponentially harder to diagnose and fix when concerns are intermingled.
State Management and Data Flow: Scalable frontend development requires effectively managing how data flows through the application and how state is shared between components. Without proper architecture, you encounter data duplication, inconsistent user experiences, and debugging nightmares that multiply exponentially with codebase size.
Cross-browser Compatibility and Maintenance: As the codebase expands, maintaining consistent behavior across different environments becomes increasingly challenging and requires careful architectural consideration.
Team Collaboration: Larger teams need clear code structure and organization to work efficiently on different components without stepping on each other's toes. Tangled codebases create friction and slow development velocity.
The Layered Stack Architecture
After careful consideration, I settled on a modern Jamstack architecture that cleanly separates concerns and scales beautifully. This approach uses Next.js for the frontend, serverless functions as middleware, and Supabase for backend services. Here's how the layers work together:—Layer 1: Frontend Web Experience LayerNext.js handles rendering and the complete user interface. This layer contains reusable React components (buttons, modals, data grids, art display cards) all pulled from a carefully curated design system library. These components are purely presentational with zero business logic or data-fetching concerns.
The key insight: this layer knows nothing about where data comes from or how business rules operate. Components simply receive data through props and render it. This isolation enabled rapid prototyping; I could experiment with layouts, themes, and user interactions without touching backend systems at all.Benefits:
• UI designers and frontend developers can work independently from backend teams
• Components remain simple, readable, and maintainable as the project grows
• Easy testing of components in isolation using tools like Storybook and Jest
—Layer 2: Intermediate API Layer (Backend for Frontend)This is the critical architectural piece that enables scalability. Serverless functions deployed through Next.js API routes create a boundary layer between the presentation tier and backend systems. This Backend for Frontend (BFF) layer serves multiple crucial functions:
Security and Authentication: Handles secure credential exchange with Supabase for user authentication, session management, and authorization checks before exposing any data to the frontend.
Data Transformation and Aggregation: The BFF bundles and transforms raw backend data into frontend-optimized shapes. For example, instead of the frontend making multiple requests and assembling data, the BFF might combine user location data, preference settings, and real-time collaboration status into a single, clean API response. This shields the frontend from complex queries and business logic.
Access Control and Privacy: Implements business rules about which data users can access. Instead of pushing this logic to the frontend (where it can be circumvented), the BFF enforces permissions and filters data server-side before sending it to clients.
Caching and Performance: Implements intelligent caching strategies, request deduplication, and data batching to optimize performance without burdening frontend code.
Direct Database Protection: The frontend never touches the database directly. All data access flows through the BFF, providing a single point for security audits, performance monitoring, and optimization.Running on Vercel, this layer scales independently and automatically. Early in Arti's development, I mocked this layer with dummy data, enabling feature prototyping at extraordinary speed. I could build location-based feed interfaces, test user interactions, and refine the experience in hours, and only later connecting the live Supabase backend.
Benefits:
• Frontend and backend teams can work in parallel with clear contracts
• Easy to modify backend data structures without breaking frontend applications
• Central point for implementing cross-cutting concerns like logging, error handling, and monitoring
• Serverless architecture provides automatic scaling and cost efficiency
—Layer 3: Backend Core LayerSupabase handles the foundation: a PostgreSQL database for persistent storage, built-in authentication services, file upload capabilities for art assets, and real-time database subscriptions for collaborative features. All business logic lives here or in the BFF layer completely isolated from direct frontend access.This architecture means the backend can evolve independently. Database schema changes, query optimizations, and business rule refinements happen without touching frontend code. The contract between frontend and BFF remains stable even as backend implementation details shift.
What I Learned and Tips for Next Time
Early iterations had too much overlap between layers, dragging down deployment velocity and creating maintenance headaches. What eventually clicked was treating the frontend as purely an "experience" layer, not a compute layer or a data access layer, just presentation.This mental model fundamentally changes how you design APIs and component interfaces. You stop asking "what data does the UI need?" and start asking "what's the minimal shape of data that cleanly represents this user experience?" This shift toward experience-oriented thinking dramatically improves architecture quality.I'm currently exploring GraphQL as a next evolution. GraphQL's flexible query language could provide even better abstraction between frontend and BFF layers, allowing frontend code to request exactly the data it needs without backend changes.The additional complexity of layered architecture does create some friction during debugging, and tracing data flow across multiple layers does require careful instrumentation. However, this cost is trivial compared to the maintainability and scalability gains. Proper monitoring with tools like Sentry transforms debugging from painful to manageable.
The Bigger Picture
Frontend scalability isn't achieved through any single technique but through thoughtful architecture decisions that respect the separation of concerns, enable team collaboration, and keep each layer focused on its specific responsibility. The BFF pattern deserves particular attention as a practice that enables teams to scale both their applications and their engineering organizations.Bottom line: Decouple early with BFF patterns and clear architectural layers. This keeps your projects breathing as they grow. If you're building something that needs to scale, implement this layered approach from the start. The initial investment in architecture pays continuous dividends in reduced complexity, faster iterations, and confident deployments.The goal isn't perfection; it's building systems that your team can confidently modify, extend, and maintain as requirements evolve and scale demands grow.

Photo by Pierre Châtel-Innocenti on Unsplash
Feb. 2026shifting focus
Working with AI
As a fullstack developer who's spent years building React/Next.js apps, I always loved the craft of coding from scratch. But after months with GitHub Copilot, especially its agent mode, something fundamental shifted in my daily workflow. It's not about less work; it's about smarter work, pushing me to refine my practice and focus on what truly adds value.
If AI can write increasingly better code, how do we adapt our practice to stay valuable and fulfilled? After working through these shifts in my own practice, I've found that the role isn't disappearing. Instead it's transforming into something more strategic and arguably more interesting.
TL;DR: AI tools have shifted my focus from writing code to architecting systems and engineering context. New standards like MCPs and Spec-driven development help AI assistants do more.
From Developer to Architect
The shift happened gradually, then all at once. Early on with Copilot, I'd let it autocomplete functions and components, saving a few keystrokes here and there. But as I got more comfortable and as the tool got better, something fundamental changed in how I approached work.My practice has evolved in two critical ways. First, conceptual work took center stage. Instead of grinding out HTML/CSS/JS boilerplate or debugging syntax errors, I now spend my time planning architectures for major features before any code gets written. While AI handles routine coding, I get to focus on architecture, problem framing, and integration: the tasks that require human judgment and domain expertise.The first main lesson I learned along the way is to never trust AI output fully. After an early async bug that made it to staging, I now review every generated line with the same scrutiny I'd apply to junior developer code.Second, quality infrastructure became non-negotiable. I've made tests, consistent code style, and naming standards the foundations of every project. ESLint and Prettier enforce style automatically, custom Copilot instructions embed our conventions directly into generation, and comprehensive test suites catch what AI misses, and it does miss things.This mirrors what Stef van Wijchen articulates in "The Self-Trivialisation of Software Development": "The frontier keeps moving … when lower level tasks become trivial, my development focus is moving to higher level problems." The value of developers increasingly lies in deciding what to build, ensuring it's architecturally sound and correct, guiding AI tools with the right constraints, and understanding the business domain deeply enough to spot what AI can't.The more I use AI in my daily practical work, the more I agree with Rahul Dinkar's article How Senior Frontend Engineers Actually Use AI at Work which highlights that senior frontend engineers effectively use AI for tasks like generating boilerplate, performing mechanical refactors, and scaffolding tests. However, AI consistently falls short in complex areas requiring deeper understanding, such as architectural decisions, performance reasoning, and debugging asynchronous issues. Ultimately, AI serves as "leverage on clarity," and they excel when the solution is well-defined but may amplify confusion when the problem itself is ambiguous.
State of AI Tools
The AI tooling landscape has exploded in the past year, and it's hard to keep up. GitHub Copilot remains my go-to for in-editor assistance after trying others like Cursor and Zed . The agent mode is a game-changer; it can implement entire features from natural language specs, refactor across multiple files, generate tests based on implementation, and suggest architectural improvements.What excites me most is the move toward agentic AI as a tool that don't just complete code but actively collaborate on development tasks. I recently used Copilot's agent mode to migrate a legacy authentication system. I provided the high-level requirements, and it generated the migration plan, implementation code, and test suite, and iteratively fixed issues as tests failed.My role as a developer now starts with providing high-level requirements of the new features along with the bigger architectural overview. And in a way not unlike TDD (Test Driven Development), tests become especially important and I find myself paying them more attention to ensure edge cases are covered and validated.Different AI tools are emerging for specific development needs too. Code review assistants that understand project conventions, documentation generators that maintain sync with code, performance analyzers that suggest optimizations, and security scanners with AI-enhanced vulnerability detection.
Emerging Standards
Here's where things get really interesting. As AI tools become more capable, the bottleneck isn't the model; it becomes the context. How do we help AI understand our projects, conventions, and constraints without overwhelming it?
Model Context Protocol (MCP) is emerging as a standard way to expose project context to AI tools. I think of it as an API for the LLM model.I've started experimenting with MCP servers that provide project structure and component relationships, coding conventions and style guides, common patterns and anti-patterns specific to our stack, and testing requirements and quality gates. Tools like Context7 and implementations like DevTools MCP are making this practical.Instead of re-explaining our architecture in every prompt, the AI can query the MCP server for relevant context. In a recent Next.js project, I set up an MCP server that knows our API layer conventions. Now when Copilot generates API routes, it automatically follows our authentication patterns, error handling standards, and response formatting, without me specifying it each time.The DevTools MCP allows AI coding assistants to see and interact with a live Chrome browser. This basically allows the LLM response and code suggestions to see how their changes affect the frontend visually and to see its network calls. In other words, it can debug its own output. In addition, it can help analyze and suggest improvements for the application’s performance, as well as simulate user interaction and run more complicated test scenarios.Beyond MCPs, there's a broader movement toward AI Engineer Optimization (AEO) and optimizing codebases to be more AI-friendly. llms.txt is a simple but powerful proposed standard that helps LLMs dramatically understand and process a webpage’s content better. It's like a robots.txt for AI inference written in Markdown, and its primary function is to direct LLMs to the most important and relevant content on a site.Anthropic's team nailed it in their context engineering guide: "As models become more capable, the challenge isn't just crafting the perfect prompt—it's thoughtfully curating what information enters the model's limited attention budget at each step."This is becoming a skill in itself. I'm now thinking about what context is essential for this task versus what's noise, how to structure information so AI can parse it efficiently, and when to provide examples versus when to rely on conventions.It's a new kind of information architecture, optimized for AI consumption.More recently, I'm excited to follow up on the latest trends in recent AI build tools. Spec-driven development is emerging as a standard for AI agents, with tools like Agent OS providing a structured context system to guide agents toward production-quality code. GitHub's Spec Kit reinforces this approach by treating specifications as executable artifacts that enable reliable, iterative development with AI coding agents. This methodology represents a significant shift in how developers collaborate with AI to build at scale.
The Road Forward
So where does all this lead? Based on my experience and where the tools are heading, I see developers evolving into what I'm calling Solutions Architects.The lines are blurring between traditionally separate roles. AI handles implementation details, so I can focus on product value. Rapid prototyping becomes trivial, enabling more exploration. The gap between idea and demo shrinks dramatically. I imagine developers being increasingly involved in product planning discussions. This would elevate the cooperation level between them and product managers, and the conversation would shift from "Can we build this?" to "Should we build this?"This connects to a broader shift I'm excited about: using AI to run inexpensive experiments at scale. I’ve written more about this in a separate article here. [link]Looking ahead, successful developers will excel at context engineering and making projects AI-friendly through new standards. Quality means designing tests and review processes that catch AI failures. Architecture and integration work involves solving the problems AI can't intuit: How do systems fit together? What are the non-obvious edge cases?My advice if you're navigating this transition:
• Start with solid foundations: tests, style guides, naming conventions. Never fully trust AI output and develop a rigorous review practice.
• Shift your focus toward architecture, problem framing, and product value. Use AI to run cheap experiments and validate ideas quickly.
• Invest in defining your AI assistant’s context. Experiment with emerging standards like MCPs.I see the future of development as being collaborative with human insight and taste aided by AI execution, and it opens up many new possibilities.

Photo by Pierre Châtel-Innocenti on Unsplash
Nov. 2025style and consistency
Design Systems
that adapt
Since my first experience building and developing webpages and up till now, I've always leaned toward minimalist UI. Simple skeleton-like frameworks like Pure.css or Bulma were my first favorites as they're lightweight and flexible, while Bootstrap felt much more heavy-handed and at times even bloated.My journey with design systems has changed across multiple projects and jobs, starting from working as a freelancer to wrangling legacy messes in enterprise gigs to crafting custom setups in modern teams. Let's chart the highlights here along with how my processes and tools have evolved in time.
TL;DR: The right design system isn't the most sophisticated one. It's the one that matches your current constraints (team size, app complexity, immediate needs) while remaining flexible enough to adapt as you grow. Ship with what your team understands, then evolve from real constraints.
A Visual Language
Beyond code and components, design systems are the visual language that defines your brand in every interaction. Consistency in color palettes, typography, spacing, and interaction patterns creates trust, and users begin to recognize and anticipate your app's behavior before they consciously think about it. When every button, card, and animation reinforces the same design language, your product feels intentional, polished, and professionally crafted rather than haphazard.This consistency extends to emotional resonance: a well-designed system conveys your brand's values through every pixel, whether that's playful and approachable or precise and authoritative. Strong design systems don't just reduce dev friction. They're the invisible thread connecting your visual identity across platforms, devices, and time. They're how users know they're experiencing your app, not someone else's.
Wrestling with UI Inconsistencies
In my first few jobs, especially those tied to Java monoliths, UIs were a patchwork: scattered CSS files, framework-locked styles, and no standards, leading to slow loads and accessibility blind spots. One standout was migrating source control from Java's old-school versioning to Git, which highlighted just how much technical debt we carried from inline hacks and unused bloat.Across projects, my north stars stayed the same: Pritortize security (vetting deps rigorously), ensure responsiveness (mobile-ready from the outset), and build in accessibility (aiming for WCAG basics). After that, it was about fostering consistency to make handoffs smoother and reducing debt so future devs (including me) wouldn't undo progress. Each job became a performance lab as well because optimizing bundles was non-negotiable for real-user speed.
Evolution
This progression played out over roles, each building on the last to handle growing complexity:—Early Days with Skinny
In my initial enterprise role, post-Java-to-Git migration, I created Skinny: a minimalist version of eBay's open-source Skin. Skin's decoupled CSS was a game-changer: Framework-agnostic styles for grids, buttons, and forms meant we could apply it broadly without React ties. It prioritized our must-haves: secure (no risky libs), responsive (flexible layouts), and accessible (semantic elements). Quick to prototype with, it slashed load times and started chipping away at legacy debt, letting us version styles cleanly in Git. I hunted for decoupled options early, favoring systems where HTML/CSS could stand alone from JS (that Bring Your Own JavaScript "BYOJ" philosophy to mix with any frontend).—Exploring Web Components
Wanting framework flexibility without JavaScript lock-in, I experimented with Lit, a lightweight library for building web components that leverage native web standards. Lit provides a component base class (LitElement) that extends the native HTMLElement with reactive state, scoped styles, and a declarative template system using JavaScript tagged template literals. This approach minimizes boilerplate and enables efficient DOM updates by only changing parts affected by state changes. With a minimal footprint of around 5 KB minified and compressed, Lit's interoperability across any HTML environment (vanilla JavaScript, TypeScript, or larger applications) made it appealing for projects needing framework independence. The library supports both tool-free prototyping and robust production workflows, making it ideal for teams wanting standards-based components without heavyweight frameworks.—The Modern Default: Tailwind and shadcn/ui: More recently, I've watched Tailwind CSS shift the entire conversation. Rather than shipping opinionated components, Tailwind provides utility-first styling that lets you compose designs quickly without context-switching between CSS files and component logic. Paired with shadcn/ui, a collection of unstyled, accessible components built on Radix UI primitives and styled with Tailwind, you get the best of both worlds: composability without lock-in, since shadcn/ui components live in your codebase as copy-pasteable source, not a black-box dependency. This approach fits teams that want design system flexibility without heavyweight frameworks. You own the code, control the styling, and can adjust components to match your exact brand language without forking libraries or fighting abstraction layers. For projects where speed and customization matter equally, this combination has become my default reach as it's opinionated about accessibility and interaction patterns (via Radix), but agnostic about how your UI actually looks.—Building a Design System for Microfrontends
Later, in a scalable product team, off-the-shelf limits hit and we needed tailored components for niche flows (e.g., collaborative tools). So, I co-led building our own design system inspired by Grommet basics with Storybook for interactive docs. Designed for microfrontend architecture, it used shared design tokens (colors, spacing) via a monorepo, ensuring harmony across independent modules without a bloated core. Deployed as an internal repo and later open-sourced, it reduced debt from prior jobs and scaled beautifully acroos multiple teams and products.You can explore the evolving design system here.—A Hybrid Approach
In my more recent role developing the Arti platform, we settled on Grommet as our foundation because our team already knew React deeply, our product was component-heavy, and the built-in accessibility meant we didn't have to bake that in ourselves. Could we have saved a few kilobytes with a leaner system? Sure. But the math was simple: Grommet meant faster shipping, fewer accessibility bugs caught in review, and a team that didn't need to context-switch between frameworks. We layered custom components as needed on top and only extended it when we genuinely found it lacking.That's the discipline: pick the right foundation for your constraints right now, then have the patience to expand within it and add the necessary tools to it. These extensions aren't added to increase complexity; they're about maintaining what you've chosen. The moment you start bolting on side systems, you've traded technical debt for architectural debt, which is often worse.
Commting to a Solid Foundation
Looking back across these roles, each choice made sense at that moment. The pattern is about matching your design system to where you actually are: your app's complexity, your team's size, and what you're solving for right now. At the same time, you want to work with a design system that is flexible enough to easily adapt to your future needs.The trap is over-engineering it. A small team building a focused product doesn't need a custom system. A simple library like Bulma gets you consistent results, ships fast, and lets you focus on product. An enterprise monolith burning cycles on accessibility bugs? A more advanced framework like Tailwind or Grommet with solid foundations out-of-the-box mean you spend energy on larger features.The experienced move is picking the one that fits your constraints and committing to it. Once you've shipped, you learn what your product actually needs versus what sounded good in theory. That's when thoughtful expansion happens, but only then. Start with a solid foundation your team understands, ship it, and evolve from real constraints, not speculative ones.

Photo by Pierre Châtel-Innocenti on Unsplash
At the edge
of Planning and Building
Why Product Egnineering
I've noticed something fundamental changing in how I work as a developer. It's not just about shipping features faster with AI assistance although that's definitely part of it. It's about how the entire relationship between product planning and technical implementation is being rewritten. When you can prototype a feature in hours instead of weeks, the whole product development process changes. Suddenly, you're not choosing between careful planning and rapid building—you can do both simultaneously.The question isn't "Should we build this?" but "Let's build three versions and see which works." This raises some interesting points: How do traditional product planning methods hold up when prototyping becomes nearly free? What happens to the PM-developer boundary when developers can turn ideas into demos before the spec is finished? How do we take advantage of cheap experiments to build better products? After working through these shifts in my own practice—moving from traditional agile sprints to more experimental approaches—I have some thoughts on where we're headed.
TL;DR: AI may create a hybrid Product Engineer role that bridges planning and implementation. When experiments are cheap, the optimal strategy shifts from perfecting one idea to rapidly testing multiple approaches and learning from the results.
Product Planning: Traditional vs. Emergent
For years, I've worked in teams following the classic agile ritual: the two-week sprint cycle with backlog grooming, sprint planning, daily standups, sprint review, and retrospective. This works really well when requirements are relatively clear, you're building known features for an established product, the team needs predictability for coordination, and stakeholders want regular visibility into progress.Traditional agile methods work well for clear requirements but struggle with discovery and innovation. Basecamp's Shape Up methodology offers an alternative approach that addresses these challenges. It uses six-week cycles with distinct phases: shaping, execution, and cool-down. This structure separates exploration from execution, uses "appetite" rather than estimates, and empowers teams to solve problems within time constraints rather than following detailed specs.What I love about this is that shaping separates exploration from execution—the discovery work happens upfront with lower commitment. It uses appetite over estimates: "We'll spend six weeks on this" rather than "This will take six weeks." Teams own the scope, not handed detailed specs but trusted to solve the problem within time bounds.
The Hybrid Role: Product Engineer
AI has transformed the distance between idea and working demo. With AI tools, I can now turn a product idea into a working prototype in hours, create multiple feature variations for comparison, and validate assumptions with real code. This has given rise to what I think of as the new Product Engineer role—a hybrid professional who operates at the intersection of product and technical domains.Product Engineers possess product intuition to understand user needs and business value, technical expertise to implement ideas rapidly with AI assistance, an experimentation mindset to validate through prototyping, and communication skills to bridge PM and technical languages. In my current role, this process involves rapid prototyping, demoing working prototypes, and refining the chosen approach, saving significant time while exploring multiple options.This is giving rise to what I think of as Product Engineers—people who operate in both domains. They have product intuition and understand user needs and business value. They have technical chops and can implement ideas rapidly with AI assistance. They have an experimentation mindset and validate through prototyping, not debate.
The Time is Right for Cheap Experiments
This connects to a broader principle I've been thinking about, inspired by Michael Schrage's work on innovation. In his research, particularly in "The Innovator's Hypothesis" and related work, Schrage argues his "5×5" principle: Five teams working on five variations of an idea will outperform one team trying to perfect a single approach.Why? Because we're bad at predicting what will work—even experts guess wrong regularly. Experiments reveal hidden insights because working prototypes expose problems that specs miss. Cheap experiments change everything since when failure is inexpensive, you can try more things.And learning compounds as each experiment improves the next one. The bottleneck in innovation isn't ideas—we have plenty. It's testing ideas fast enough to find what works.Here's what's exciting: AI has made technical experiments dramatically cheaper. In the old world, building a prototype took two to four weeks of developer time, cost per experiment was ten to twenty thousand dollars in loaded cost, so we were conservative about what we tested.
A Possible New Model
So what does this all mean for how we actually build products? I see these themes converging into a new product development model with three phases. Phase one is problem shaping lasting one to two weeks where a Product Engineer and PM explore the problem space, use rapid prototypes to test assumptions, identify two to three viable approaches, and define appetite around time and scope boundaries.Phase two is experimental building lasting four to six weeks where the team implements the best approach from shaping, continues running mini-experiments on details, holds regular demos with real working code, and stays comfortable pivoting based on the team learns.Phase three is cool-down lasting one to two weeks for individual experiments and technical cleanup, retrospective on what we learned, and shaping starts for the next cycle.Key differences from traditional agile: prototyping is explicit, not hidden in "research spikes." Experiments inform commitment, not the reverse. Product Engineers bridge planning and implementation. And speed comes from validating fast, not estimating perfectly.
Thank you
Adipiscing mi ac commodo aliquet ultricies viverra. Massa placerat duis ultricies lacus sed turpis sit fulminare justo veroeros etiam.